

This article is also available in the following languages: Portuguese.
In this article, we will understand the basics of Search Engine Optimization (SEO), and of the HTML’s format and syntax. We will also learn how to implement better tags on our websites, that can help us to reach better results on search engines, by investigating how they do work, and what are the meta tags that they understand.
💡 If you are not familiar with the HTML syntax, you should check my article “CSS and HTML Explained for Absolute Beginners: Part 1” before continue on this current one, as some markup language knowledge may be necessary.
Introduction
Suppose you are getting into a new author, and walk to the next bookstore, on your neighborhood, hoping that you will find this person’s new book there. How do you start searching for it?
There are many options that may help you on this job: (a) you ask the salesperson, by giving some information about the book; (b) you walk through the aisles, looking for the specific category where the book belongs; or, (c) you look at every single book in this bookstore, one by one, looking for the specific cover that contains the information you’re looking for.

As you can see, some of these choices may take a while, but they all have one thing in common: the document’s metadata. It means there are some information on these objects that can be used for catalog, and also for better searching purposes.
This is the basic of Search Engine Optimization, or SEO techniques, a process meant to optimize the way we search for specific things on the internet. Let’s investigate how this works, and how we can develop better implementations on our websites or applications, in order to reach better positions when users search for specific keywords on their favorite search engines.
What is SEO?
Search Engine Optimization (SEO) is a set of techniques in order to make the web content search-friendly, by making the search engines “understand” our website, and lead users to find us. The small improvements that we make, result in more relevant users viewing our content, and also help us to promote and monetize web content.
There are many experts on the internet that can help us to improve our visibility on those page’s results, and also to provide useful services. Let’s understand how we can apply some of these techniques by following the HTML standards.

“Search Engine Optimization”, by Gerd Altmann from Pixabay
How to insert meta tags in HTML
Before we get started, take a minute to check the metadata information used on this current webpage.
Above the web browser’s address bar, the title, and the icon — a.k.a. favicon, the “favorite icon” — are presented even before the page is fully rendered. See how our web browser already collect some of this data? Under the hood, when a request is made to a web server, our web browser is looking for information like this:
<!doctype html>
<html lang="en" dir="ltr">
<head>
<meta name="viewport" content="width=device-width,initial-scale=1">
<link rel="icon" href="/favicon.png">
[...]
<title>My simple web page</title>
<meta name="description" content="In order to fully understand SEO, we have to start by the basics, learning its fundamentals.">
[...]
</head>
💡 Some browsers provide better information about the metadata gathered from the current webpage. If you’re using Mozilla Firefox, you can open the Site Information panel by pressing
Ctrl + Ion your PC, or by following this guide. The opened window should look like this:
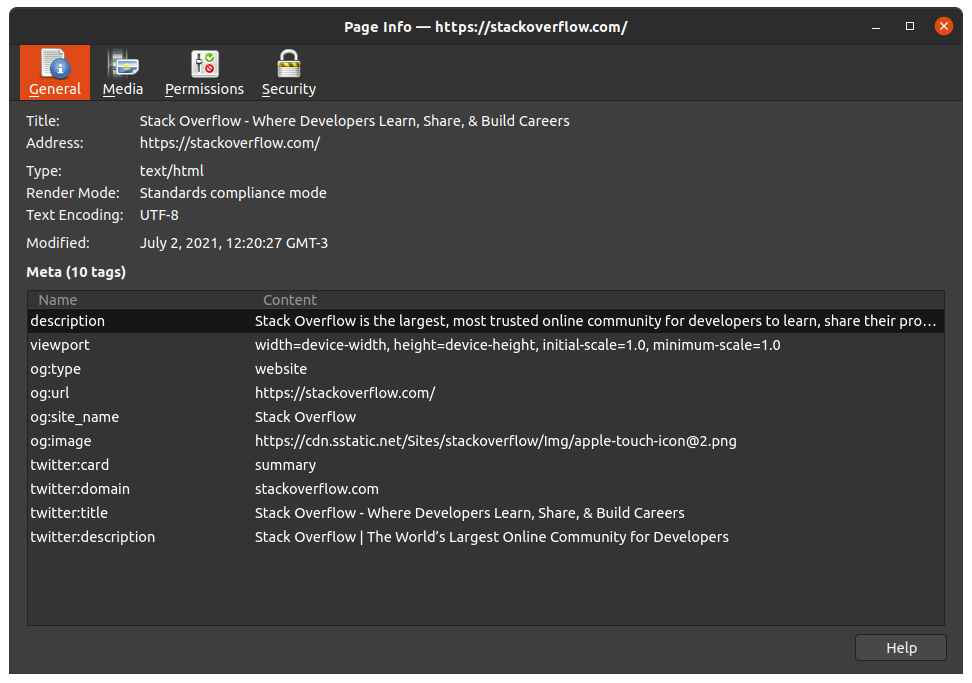
StackOverflow’s homepage — yes, they do have a homepage! — seen in Firefox’s Site Information panel.
Even if you don’t fully understand HTML yet, notice these pieces of information:
- The source-code tells the web browser that this is an HTML-type document;
- The second line specifies that the following HTML elements are displayed in the English language, and the “left-to-right” (
LTR) direction; - There are some
viewportdefinitions for rendering the current webpage; - There are, also, some values provided for the
icon, thetitle, and adescriptionabout this page.
HTML is not rocket science, so we can easily insert meta tags in our HTML file by adding it to the top of our content, inside the HTML’s head element.
The head element is meant to provide some information about the page, such as rendering definitions, links, style-sheets, and scripts. Most of this metadata are not human-readable, and will not be displayed on the page, but will be only interpreted by the web server, and by the client’s web browser.
The search engines usually collect data from the head element to provide better results, which means that we can insert meta tags to improve the visibility of our webpages and applications, like by following the HTML’s formatting syntax.
HTML’s formatting syntax
The HTML’s formatting syntax is the set of rules that structure an HTML file, so its content can be recognized by the web browser and correctly rendered for the users’ navigation.
There are many elements defined on the HTML Standards, and developers had also implemented non-standard elements and global attributes on their applications.
For the purposes of this article, we will cover only some of those that can be understood by SEO techniques, so you can implement it on your own website or application to achieve better results.
The document element 📃
The first step on creating an HTML file is actually informing that it is an HTML file.
According to the HTML Standard, by the Web Hypertext Application Technology Working Group (WHATWG), a community founded by the leading web browser vendors in 2004:
The
htmlelement represents the root of an HTML document.
In other words, it refers to the single element from where all the HTML’s elements belong to. You can think it as node tree: the whole document is a document node; so other HTML elements are hierarchical nodes, like this:
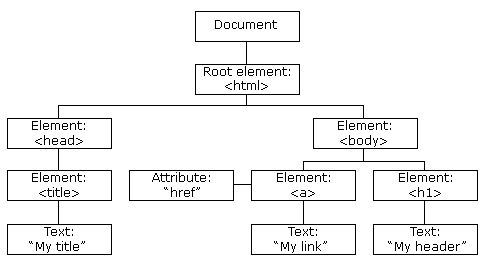
The HTML DOM nodes structure. Image from W3Schools.
The document tree 🌳
The way most search engines work is by traveling relevant parts of the entire document, and then gathering information from its nodes, and creating relationships between the element and its content, such as texts, by looking for HTML’s p elements (for the paragraphs), or images and its caption — like this one:
<figure>
<img src="/media/cc0-images/elephant-660-480.jpg" alt="Elephant at sunset">
<figcaption>An elephant at sunset</figcaption>
</figure>
Notice the alt attribute on the example above: it can be used by screen readers, for blind and visually impaired people, so they can know what this image is about; but also for SEO purposes, as we can describe for the search engine what this figure is about, and how it’s related to near text.
Talking about web accessibility, we should avoid placing texts inside images, as it won’t be read for many users. Instead, we can use a relevant image near a piece of text explaining what this is about.
💡 The best practice is to place the most important figure near the top of the webpage, like a banner image, and the other images near its context, such as the relevant text or section’s heading.
The document metadata 📔
Another great way to provide information for the search engine is by using meta tags. In the HTML document, it can be provided right on the front matter, inside the head element. For example:
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1.0">
<meta name="generator" content="WordPress 5.6">
<title>The document metadata</title>
<meta name="author" content="John Doe">
<meta name="description" content="This article explains the HTML metadata">
<meta name="keywords" content="html,metadata,rfc">
<link rel="alternate" type="application/atom+xml" href="blog-posts.xml">
<link rel="canonical" href="http://www.example.com/html/">
<link rel="license" href="https://creativecommons.org/licenses/by/4.0/">
</head>
💡 According to the HTML5 Standard, void elements, such as
linkandmetatags are self-closing, as they don’t have any content. It means you can end them by just typing>, instead of/>. Other void elements include:area,base,br,col,embed,hr,img,input,param,source,track, andwbr.
Let’s understand each one of these elements used in our example code.
HTML head elements
The meta tag 🧬
First, the meta tag is used for defining metadata about the HTML file, and can modify the way web browsers render the document.
The MDN Web Docs has a great list about the values that can be assigned to the meta tag’s name attribute, such as author, description, generator, and keywords. Most of them are self-descriptive, and automatically informed by modern frameworks already.
Let’s revisit our previous example. The first three meta tags can be useful: (i) to inform the characters encoding — we’re using UTF-8, the default charset —; (ii) to specify the device’s size (also to enable the responsive behavior); and (iii) to identify the software that generated the webpage.
These three lines below can be used to describe the name of one of the page’s authors, a brief summary of the document — modern web browsers may use it as the default description of bookmarked pages —, and some keywords (separated by comma) related to the current page’s content:
<meta name="author" content="John Doe">
<meta name="description" content="This article explains the HTML metadata">
<meta name="keywords" content="html,metadata,rfc">
💡 Most of the search engines use this metadata to provide a short description of the webpage on their results, so using a good mix of keyword phrases can lead us to make better results. But be careful: numerous unnecessary keywords should be avoided, as they may harm your position.
If dealing with explicit content, it is strongly recommended by most of the search engines to specify the rating metadata, so it won’t be included in the search results for users that are not allowed, don’t want, or don’t expect to find these, when using search filters, like Google’s SafeSearch. It can be done by including one of the following meta tags:
<meta name="rating" content="adult" />
<meta name="rating" content="RTA-5042-1996-1400-1577-RTA" />
Another thing to notice about the meta tag is that many search engines may change the search result title if they notice an alternative text, inside the webpage’s content, that better indicates their relevance to the users’ query. According to Google Search Central, it occurs when “the title tag as specified by a website owner is limited to being static, fixed regardless of the query”, so the search result title might differ from the title tag defined in the HTML file.
The link tag ⛓️
Sometimes, developers need to establish connections to use external resources from a different location, for many reasons, such as to avoid repetition of code and patterns, so replacing it with another source also reduces the size of the single file. This can be done by using the link element.
The External Resource Link element, the HTML’s <link> tag, tells the web browser to get this file, and use its content in the current web page. For example:
<link rel="icon" href="favicon.png">
<link href="default-stylesheet.css" rel="stylesheet">
<link href="https://example.com/css/print.css" rel="stylesheet" media="print">
<link href="mobile.css" rel="stylesheet" media="screen and (max-width: 576px)">
In this example, we are informing the browser to locate the default CSS file, used for most of the media types, in the default-stylesheet.css. Notice that files can also be located outside the current page’s directory, as we are reaching the https://example.com/css/print.css file from a different web server.
The media attribute specifies that this resource should only be used by the web browser when the media condition is true. So, in our example, if we are trying to print this web page, our web browser will render the page according to the style-sheets located in that file.
For targeting printers, we can add our code inside the media breakpoint in our CSS file, like this:
@media print {
.banner > p {
background-color: #ffffff;
color: #000000;
}
}
💡 HTML respects the order of the information provided, so we can set a new CSS file to override the previous one: by adding an external resource link element after the
default-stylesheet.cssline, in our example.
The same applies to the mobile.css file: if we are opening this page on a device which screen is 576px or less, the browser will render the webpage according to its file.
💡 There are some common breakpoints, based on the general screen size ranges, such as: 576px (small devices), 768px (medium devices), 992px (large devices), and 1200px (extra-large devices).

“Responsive Web Design”, by Clovis Cheminot from Pixabay
For better SEO results, we should use the rel attribute as well, that can set a relationship between some linked resources and our current webpage.
According to MDN Web Docs, the rel attribute must express tokens that are semantically valid for both machines and humans. In our example, we already used three of them:
<link rel="alternate" type="application/atom+xml" href="blog-posts.xml">
<link rel="canonical" href="http://www.example.com/html/">
<link rel="license" href="https://creativecommons.org/licenses/by/4.0/">
Let’s understand what does each one of them:
- The
alternatevalue describes other representations of the current document, such as a syndication feed, or an alternative format and language, intended for other media types. In our example, we are demonstrating that there is an Atom Feed for our blog-posts as an alternate representation. - The
canonicalvalue should be use if there is a single page that can be accessed on multiple URLs, or different pages containing the same content. It may occur when there are duplicate versions of the same page, such asexample.com/html/andexample.com/?p=html, so all the other URLs with similar content will be considered duplicate URLs and crawled less often.
💡 Many developers usually post the same content on multiple blogging platform, or information channels, to engage a larger audience. This technique is known as “crossposting”, and should be used along with the
canonicalURL, so search engines can prioritize the one that is the most representative from a set of the duplicate pages.
- The
licensevalue indicates the licensing information for the current element or webpage. It can be used on the<a>,<area>,<form>, or<link>HTML elements, and so provided a hyperlink with the rules and declarations, like this:
<a rel="license" href="http://creativecommons.org/licenses/by/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by/4.0/88x31.png" /></a><br />This work is licensed under a <a rel="license" href="http://creativecommons.org/licenses/by/4.0/">Creative Commons Attribution 4.0 International License</a>.
💡 The synonym
copyrightis incorrect and must be avoided, although recognized by many web browsers and search engines.
The link tag, however, can’t be used for loading scripts: instead, we can use the script tag.
The script tag 🕹️
The script tag is used for embed executable code, and is typically used to include JavaScript code. It can also contain data, such as JSON (JavaScript Object Notation), that can be processed in our web page or application.
As well as the link tags, script elements can refer to JavaScript code located in another web server or directory, like this example:
<script src="https://cdn.jsdelivr.net/npm/jquery@3.6.0/dist/jquery.min.js" integrity="sha256-/xUj+3OJU5yExlq6GSYGSHk7tPXikynS7ogEvDej/m4=" crossorigin="anonymous"></script>
Notice we are using the integrity and the crossorigin attributes when adding this request to an external web server. It is a good practice, in order to create more secure applications that the web browser check the response.
- The
integrityattribute prevents web browser to load content that doesn’t match with the expected response from the web server. It contains a hash of a resource as its value, that ensures that the file was received unmodified and delivered without unexpected manipulation. - The
crossoriginattribute defines how the element handles cross-origin requests, by adding anOriginfield into the HTTP Request to a server from a different origin. It provides support for Cross-Origin Resource Sharing (CORS) mechanism, and can be set to eitheranonymous(default), oruse-credentialsvalues: the first one creates CORS requests with the credentials flag set tosame-origin; the second one, with the credentials flag set toinclude.
In our example, the web browser won’t execute the code if the delivered file doesn’t match with the hash that was informed, using the SHA-256 cryptographic hash algorithm.
💡 HTML’s
linkandscripttags can implement theintegrityandcrossoriginin order to provide better security, by allowing proper verification of the received data and its source.
That code can be implemented in the head or in the body of our HTML file, so the web browser would request for the file before or after the page’s content is fully loaded. Also, it can be loaded in parallel with the rendering of the webpage’s elements, asynchronously, or synchronously.
Developers typically insert the script element right after all the elements of the webpage are defined: in general, this way you can ensure the user will not be presented to a blank page until all the scripts are loaded, what can take some time depending on the users’ network.
💡 For the purposes of this article, we won’t cover the pros and cons of inserting the
scriptelement on theheador thebodyelement yet, nor doing it synchronously or asynchronously, as these topics require an article for themselves. In fact, you can follow this series as we will learn it in another time.
In SEO terms, placing the link and script tags inside the head or body element shouldn’t matter, as search engine crawlers usually won’t read scripts or style-sheets, rather than our HTML content. On the other hand, their placement may impact users’ experience, and the order of their declarations matter to other scripts that use them as dependencies.
Conclusion
We’re done, so let’s recap. We covered the basics of SEO techniques, and how to insert meta tags using HTML. Then, we learned about the document’s elements and tree. Finally, we covered a few HTML head elements, such as the meta, link, and script tags, and how to use it correctly in order to achieve better search engine results.
In the next article of this series, we will cover the HTML’s body element, and how it can be implemented for better SEO results. Make sure to follow it. 🏆
Next steps 🚶
There are many protocols that enhances the power of SEO techniques, and we can apply them to our webpage, in order to make better results. If you’d like to know about them, make sure to follow this series, as we will continue exploring how to make use of better SEO techniques.
If you have any questions or suggestions about these subjects, please make a comment below. 📣
References 🧩
[1] The Document Metadata (Header) element - HTML: HyperText Markup Language | MDN. (2021, June 2). MDN Web Docs. https://developer.mozilla.org/en-US/docs/Web/HTML/Element/head.
[2] The External Resource Link element - HTML: HyperText Markup Language | MDN. (2021, June 9). MDN Web Docs. https://developer.mozilla.org/en-US/docs/Web/HTML/Element/link.
[3] The metadata element - HTML: HyperText Markup Language | MDN. (2021, June 2). MDN Web Docs. https://developer.mozilla.org/en-US/docs/Web/HTML/Element/meta.
[4] The Script element - HTML: HyperText Markup Language | MDN. (2021, June 2). MDN Web Docs. https://developer.mozilla.org/en-US/docs/Web/HTML/Element/script.
[5] Consolidate Duplicate URLs with Canonicals | Google Search Central. (n.d.). Google Developers. Retrieved July 5, 2021, from https://developers.google.com/search/docs/advanced/crawling/consolidate-duplicate-urls.
[6] HTML attribute: crossorigin - HTML: HyperText Markup Language | MDN. (2021, May 26). MDN Web Docs. https://developer.mozilla.org/en-US/docs/Web/HTML/Attributes/crossorigin.
[7] HTML attribute: rel - HTML: HyperText Markup Language | MDN. (2021, June 22). MDN Web Docs. https://developer.mozilla.org/en-US/docs/Web/HTML/Attributes/rel.
[8] HTML Standard. (2021). WHATWG. https://html.spec.whatwg.org/.
[9] SEO Starter Guide: The Basics | Google Search Central. (n.d.). Google Developers. Retrieved July 2, 2021, from https://developers.google.com/search/docs/beginner/seo-starter-guide.